LeADS Year in Review: 2022
As the year 2022 is coming to an end it is a good point in time to look back at the first LeADS year of our 15 ESRs. In November 2021 their collective research journey started to become Legality Attentive Data Scientists and to engage in research in four crossroads, i. e. major challenges that still need to be addressed in data-driven societies: 1. Privacy vs Intellectual Property 2. Trust in Data Processing & Algorithmic Design 3. Data Ownership 4. Empowering Individuals.
More than 7 Weeks of Intensive Interdisciplinary Training
On four occasions the ESRs met to attend a cross-interdisciplinary training program which constitutes a fundamental part of the LeADS project. Being capable of fully understanding the challenges posed by the digital transformation and data economy requires knowledge in different fields such as computer science, law, and economics. The project has therefore been structured around various training modules that together aim at training a new generation of researchers that become experts in both law and data science capable of working within and across the two disciplines.
Between November-December 2021, the ESRs first met each other in Pisa at Scuola Superiore Sant’Anna for their first three weeks of training focusing on a variety of topics ranging from big data analytics and applications, data mining and machine learning, or research ethics and methodology.
Between March and April 2022, the ESRs met again for two weeks Pisa. Whereas the first training modules involved mainly subjects related to computer and data science, this training module focussed more on the legal perspective. The ESRs were taught various topics such as EU cybersecurity law, data protection law, and how AI technology challenges the regulatory framework of intellectual property.
The next training module brought the ESRs to the beautiful island of Crete. In addition to courses on law and data science, the ESRs were divided into interdisciplinary groups for practical sessions to deploy a smart contract and to analyse and identify weaknesses in a security protocol.
Finally, the last module brought the ESRs together in Kraków at Jagiellonian University in September. The last training module concluded with reflections on data and ownership as well as discussions on problems the ESRs have encountered throughout their first year of research.

ESRs on their first day in Kraków
Throughout all training modules, the ESRs benefitted from the combined academic expertise that is available at the 7 beneficiaries of the Leads project (Scuola Superiore Sant’Anna, University of Luxembourg, Université Toulouse III – Paul Sabatier, Vrije Universiteit Brussel, Jagiellonian University, University of Piraeus, and Italian National Research Council (CNR)). In addition to courses taught by academics, the ESRs also had the chance to get insights into how problems and current discussions in the data economy are perceived by businesses, thanks to the active participation of the LeADS partners (Innov-Acts, ΒΥΤΕ COMPUTER S.A., Intel, the Italian Data Protection Authority, the Italian Competition Authority, Tellu, INDRA, and MMI).
 Finally, in addition to these conventional learning practices, the ESRs also met at IRIT, Toulouse for the Technology Innovation in Law Laboratories (TILL) workshop. These two-part workshop series in the LeADS training program present the ESRs with the opportunity to do hands-on exploration of practical cases. Three different groups of ESRs had to solve challenges that were provided by LeADS partners (Indra, TELLU, and the Italian Competition Authority). The workshop provided the ESRs with the opportunity to translate their knowledge to concrete cases and receive feedback on the solutions which they developed.
Finally, in addition to these conventional learning practices, the ESRs also met at IRIT, Toulouse for the Technology Innovation in Law Laboratories (TILL) workshop. These two-part workshop series in the LeADS training program present the ESRs with the opportunity to do hands-on exploration of practical cases. Three different groups of ESRs had to solve challenges that were provided by LeADS partners (Indra, TELLU, and the Italian Competition Authority). The workshop provided the ESRs with the opportunity to translate their knowledge to concrete cases and receive feedback on the solutions which they developed.
The First year of Research
One of the first tasks of the ESRs consisted of drafting an individual personal career and skills development plan 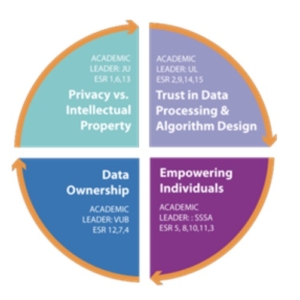 where they had to individually outline their planned activities and an evaluation of training needs and career goals for the upcoming years. Furthermore, the ESRs launched their research by drafting a research plan where they detailed research questions, methods, and proposed a first state-of-the-art analysis of the field of their own topic. During periodic meetings in the four crossroads of the LeADS project, the researchers presented their individual advances and discussed potential challenges. These early discussions allowed the ESRs to identify synergies and how their individual research could contribute to these four overarching challenges.
where they had to individually outline their planned activities and an evaluation of training needs and career goals for the upcoming years. Furthermore, the ESRs launched their research by drafting a research plan where they detailed research questions, methods, and proposed a first state-of-the-art analysis of the field of their own topic. During periodic meetings in the four crossroads of the LeADS project, the researchers presented their individual advances and discussed potential challenges. These early discussions allowed the ESRs to identify synergies and how their individual research could contribute to these four overarching challenges.
In addition to their individual research, the ESRs started collaborating closely together within the four crossroads since the beginning of their research journeys. The ESRs engaged with each other’s topics to create a collective report that has been nourished from the individual and collective research. Since the crossroads are composed of researchers from different academic backgrounds, discussions surrounding the different topics were interdisciplinary involving diverse perspectives from law, computer and data science, and economics. During regular meetings the Crossroads were therefore shaped through different perspectives. The result of this intensive process has been a 180-pages long report that constituted the first scientific output of the LeADS project and functions as a backbone for the upcoming research activities. Currently, the ESRs are working in inter-crossroads groups to collectively write working papers on diverse topics such as data governance models, data portability, or data ownership by design that will be published during the second trimester of 2023.
The First Year of Discussing and Presenting Research
Throughout 2022, several conferences have been organised by the LeADS consortium to discuss the latest developments in regulating the data economy. For Data Privacy Day an awareness conference on the explainability of AI was organised in collaboration with Brussels Privacy Hub and involved a panel of distinguished speakers such as Paul Nemitz of the European Commission, and Fosca Giannotti of Scuola Normale Superiore and CNR.
On two occasions in Crete and Toulouse, the ESRs had the opportunity to present their research at conferences during collective poster sessions. Further conferences and awareness panels were oftentimes organised with active participation of ESRs, such as the SoBigData++ and LeADS joint awareness panel on dynamic consent.
during collective poster sessions. Further conferences and awareness panels were oftentimes organised with active participation of ESRs, such as the SoBigData++ and LeADS joint awareness panel on dynamic consent.
At the annual Computers, Privacy and Data Protection conference (CPDP), ESRs were participating in a dissemination and public engagement activity and many of the LeADS project beneficiaries’ contributed to the conference during panels and talks. During Researchers’ Night ESRs participated in various events in different countries, such as in Greece, Italy, Poland, or France. ESRs also individually applied and went to international conferences to present their research like in Warsaw, Seoul, Roskilde, Madrid, or Utrecht. ESRs filmed research pitches and used the LeADS blog to communicate on diverse topics such as critical reflections on Europol, European Health Data Spaces, predictive justice, data property, the data act, or data portability.
Finally, the research by ESRs got published in journals on topics such as consent, child protection in online games, the Data Act and B2G data sharing or consumer protection.
The first year of the ESRs research journey has been an exciting, challenging, and rewarding experience for all participating researchers. It brought together academics from different scientific and cultural backgrounds who are united in their passion on doing research across disciplines. We are very much grateful for the commitment of the multitude of people who have been actively contributing to the advancement and ongoing success of the LeADS project. We are looking forward to the upcoming year which is shaping up to be an even more productive year, with further opportunities for research and new collaborations.



 The third and final se
The third and final se







 third annual conference organised by the Digital Legal Lab, which is a research network that is constituted of Tilburg University, University of Amsterdam, Radbound University Nijmegen, and Maastricht University. The topic of the conference was dedicated to law and technology and focused on a wide variety of topics such as responsible data sharing, enforcement and the use of technology, the recently proposed and passed EU data laws, and involved as keynote speakers Sandra Wachter from the Oxford Internet Institute and Thomas Streinz from NYU School of Law (for more information consult the
third annual conference organised by the Digital Legal Lab, which is a research network that is constituted of Tilburg University, University of Amsterdam, Radbound University Nijmegen, and Maastricht University. The topic of the conference was dedicated to law and technology and focused on a wide variety of topics such as responsible data sharing, enforcement and the use of technology, the recently proposed and passed EU data laws, and involved as keynote speakers Sandra Wachter from the Oxford Internet Institute and Thomas Streinz from NYU School of Law (for more information consult the 
 public emergencies and situations in which the lack of data prevents the public sector from fulfilling a specific task in the public interest. In a general analysis of Chapter V, Barbara expressed that some recent modifications made by the Czech Presidency gave the Proposal a different dimension especially when it comes to the possibility of the development of smart cities. The adoption of a more detailed Recital 58, which now defines guidance on what can be considered lawful tasks in the public interest, opens the path to a discreet development of smart cities. The modifications also have enhanced the connections of the Act with other regulations, especially with the GDPR, demanding stricter personal data protection measures by the public sector, a matter that was a source of criticism by many opinions on the Proposal.
public emergencies and situations in which the lack of data prevents the public sector from fulfilling a specific task in the public interest. In a general analysis of Chapter V, Barbara expressed that some recent modifications made by the Czech Presidency gave the Proposal a different dimension especially when it comes to the possibility of the development of smart cities. The adoption of a more detailed Recital 58, which now defines guidance on what can be considered lawful tasks in the public interest, opens the path to a discreet development of smart cities. The modifications also have enhanced the connections of the Act with other regulations, especially with the GDPR, demanding stricter personal data protection measures by the public sector, a matter that was a source of criticism by many opinions on the Proposal.

 Early Stage Researcher Barbara Lazarotto (ESR 7) presented her research at the
Early Stage Researcher Barbara Lazarotto (ESR 7) presented her research at the